import numpy as np
import pandas as pd
data=pd.read_csv('d.csv', encoding='euc-kr')
data
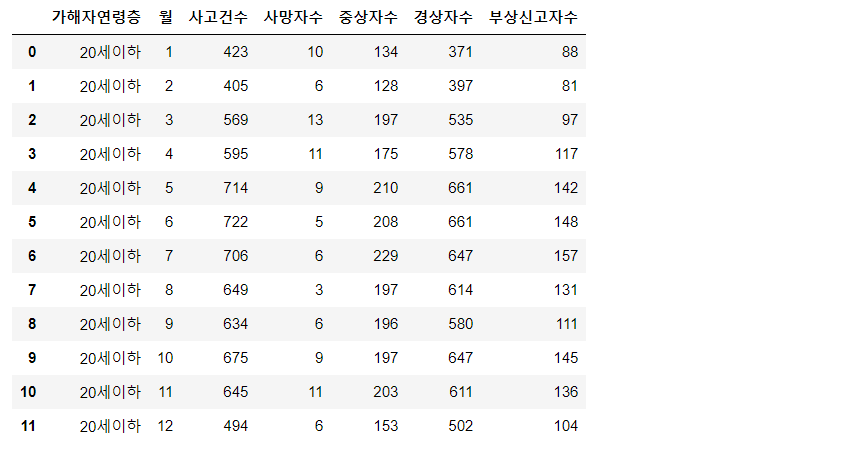
a=data[data.columns].loc[:11]
a
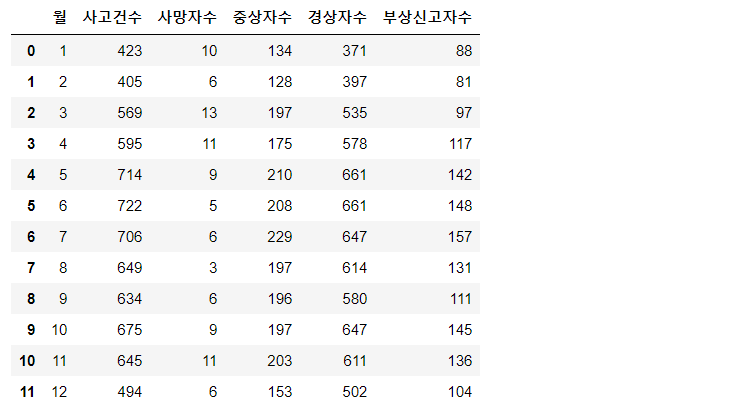
a = data[['월','사고건수','사망자수','중상자수','경상자수','부상신고자수']].loc[:11]
a
val = a.values
title = data['가해자연령층'][0]
cols = [[title,title,title,title,title,title],data.columns[1:]]
x = pd.DataFrame(val, columns=cols)
x
#배열명[컬럼명]
#배열명.loc[인덱스명]
#a.data[data.cols = [data.columns[1:]].loc[:11] #원하는 요소만 추출
tabs = []
idx = ['1월','2월','3월','4월','5월','6월','7월','8월','9월','10월','11월','12월']
cnt = len(data)//12 # / 1개면 실수로 계산, // 2개면 정수로 계산
for i in range(0, cnt):
y= i*12
title = data['가해자연령층'][y]
vals = data[data.columns[2:]].loc[y:y+11]
cols = [[title,title,title,title,title],data.columns[2:]]
x = pd.DataFrame(vals.values, columns = cols, index=idx)
tabs.append(x)
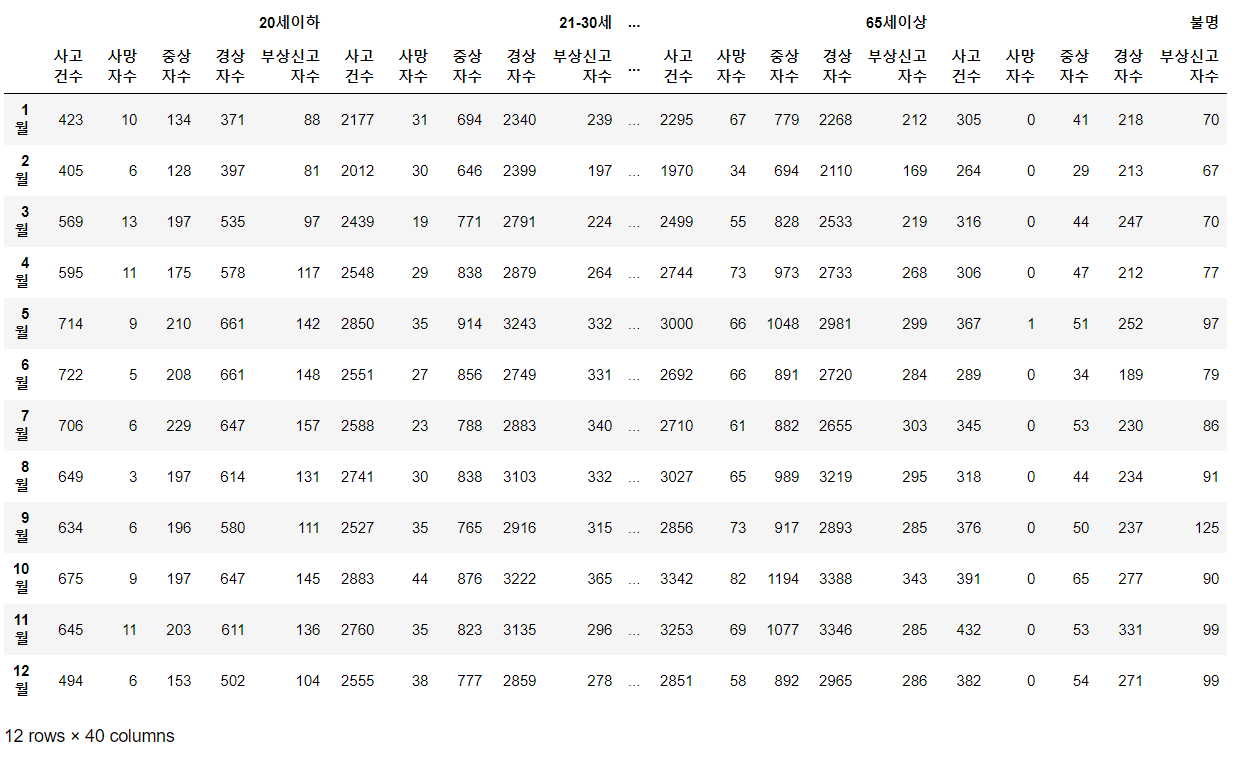
tabs
res = tabs[0]
res=tabs[0]
for i in range(1, len(tabs)):
res = res.join(tabs[i])
res
#연령별 최대 사고 발생월과 사고수
for i in tabs:
#m = i['20세이하',사고건수'].max() #하드코드 불가능
#x = i['20세이하','사고건수'].argmax()
m = i[i.columns[0]].max()
x = i[i.columns[0]].argmax()
print(i.columns[0][0],'의 최대 사고건수:',m, ' / 발생 월:',idx[x] )
#연령별 12개월의 사고발생 총건, 총 사망자수
for i in tabs:
s = i[i.columns[0]].sum()
d = i[i.columns[1]].sum()
print(i.columns[0][0],'의 사고발생 총 건:',s, ' / 총 사망자수:',d)
#연령별 12개월 사고 발생 평균 값
for i in tabs:
m = i[i.columns[0]].mean()
print(i.columns[0][0],'의 사고 발생 평균:',m)
import numpy as np
#파일 내용을 한 줄 씩 읽음
f = open('./stu_data.txt', 'r')
datas = []
while True:
s = f.readline() # s: '1, aaa, 43, 65, 78 \n'
if s == '':
break
s = s.split('\n')[0] #엔터를 잘라냄 -> s: '1, aaa, 43, 465, 78'
stu = s.split(',') # stu: ['1', 'aaa', '43', '65', '78']
for i in range(0, 2):
stu.append(0)
datas.append(stu)
f.close()
datas
여기에서 s.split('\n')[0]는 \n을 기준으로 두 조각(예를들어, aaa,43,54,65\n 이 있다면 \n을 기준으로 앞과 뒤를 나누게 되어 두조각이 됌)에서 0번째 방에 해당하는 앞 조각만 사용하겠다는 뜻이다.
# datas리스트를 numpy 배열로 변환
arr = np.array(datas)
arr
# 각 학생의 이름만 추출
names = arr[:,0]
names
# 각 학생의 점수 추출
score = arr[:, 1:]
score
#점수 배열 요소 타입을 float으로 변경
x = arr[:, 1:]
score = x.astype(np.float32
score
#모든 줄의 총점, 평균 계산
'''
for i in score:
k = i[1:4] # k: [국,영,수]
sum1 = k.sum()
i[4]=sum1
i[5]=sum1/3
'''
score[:,4] = score[:,1:4].sum(axis=1) #axis=1 : 가로줄
score[:,5] = score[:,4]/3
score
print('각 학생의 총점,평균')
for i in range(0, 5):
print(names[i], end='\t')
print(score[i])